13th December 2016 #cli #dmg #hdiutil #keychain #mac #security Macでたくさんのファイルをひとまとめにするのであればzipで圧縮するよりも、ディスクイメージファイルにしたほうが便利なこともあります。zipだと標準では中身を確認するのに毎回どこかに展開しないといけないですし、ファイルの内容を変更するのも面倒です。zip用のツールを使えばおそらくそれらも解決できると思いますが、個人的にはディスクイメージファイル(.dmg)を使うことの方が多いです。
ディスクイメージファイルは外付けディスクのようなイメージでマウントして使えます。macOSに標準添付されている「ディスクユーティリティー」ツールを使えばこのイメージファイルを簡単に作ることができます。読み取り専用、読み書き可能、暗号化、圧縮などオプションを選ぶこともできます。
終了したプロジェクトのファイル一式は.dmgファイルとしてまとめていますが、まとめたいプロジェクトファイルがたくさんあったり、ワークフローを自動化したいとなってくるとコマンドライン操作を覚えると便利です。
ディスクイメージファイルの作成
hdiutilコマンドを使うとディスクイメージファイルの作成や設定変更、ディスクイメージファイルのマウント、アンマウントなどさまざま操作可能です。詳しくはman hdiutilをご参照いただくとして手元での利用例をご紹介します。
フォルダ以下にあるサブフォルダをそれぞれ.dmgとして一括変換したい場合に使っているスクリプトです。それぞれ一応暗号化しておこうということで、暗号化用のパスワードを$HOME/.dmg-passwordというファイルにあらかじめ格納してあります。パスワードファイルには最後に改行が入らないようにつくっておいてください。
あとパーミッションも chmod 600 $HOME/.dmg-passwordなど他者から読み出せないようにしておきます。そうはいっても、後述しますが一連のプロセスはさほど安全性が高いわけではありませんので「添付ファイルはパスワードつきzipでパスワードは別メールですぐ送信!」とあまり変わらないセキュリティーレベルとお考えいただいていいかと思います。
#!/bin/sh
if [ $# -lt 2 ]; then
echo $0 SRC_DIR DEST_DIR
exit 1
fi
SRC=$1
DST=$2
PWD="$HOME/.dmg-password"
if [ ! -e $PWD ]; then
echo Disk Image password not found
exit 2
fi
for t in "$SRC"/*; do
if [ -d "$t" ]; then
echo Creating: $t
n=$(basename $t)
cat $PWD | \
hdiutil create \
-srcfolder "$t" \
-fs HFS+ \
-encryption AES-128 \
-format UDBZ \
-stdinpass \
"$DST/$n.dmg"
fi
done
ディスクイメージファイルのパスワードをKeyChainにプリセットしておく
暗号化しておいたのはいいですが、作成したディスクイメージファイルを開く際にいちいちパスワードを入力するのは面倒です。Finderからダブルクリックしてマウントしようとしたときに聞かれるパスワードダイアログはコピー&ペーストを受け入れてくれないというのもさらに面倒さを増しています。
パスワードをキーチェインに記憶させるというオプションがありますが、あらかじめコマンドラインから記憶させておけばいいという発想です。
ディスクイメージファイルに対するパスワードは一般パスワードとして各ディスクイメージファイルのUUIDと対応して管理されています。このUUIDは
$ hdiutil isencrypted ディスクイメージファイル.dmg
というようにisencryptedオプションで知ることができます。キーチェインにパスワードを追加するには
$ security add-generic-password -a (上記のUUID) -D "disk image password" -s (ファイル名).dmg -w (パスワード)
というように実行すればよいでしょう。securityコマンドの大変残念な点はhdiutilの-stdinpassのように標準入力からパスワードを受け取る手段がどうやらなさそうな点です。
コマンド引数として実行してしまうと、シェルの履歴に残ったり、psコマンドなどでパスワードが漏えいしてしまうケースがあります。このような点から上述のように「添付ファイルはパスワードつきzipでパスワードは別メールですぐ送信!」というセキュリティーレベルとたいして変わらないと思っています。
さて、上記を合わせて次のようなスクリプトにしてあります。
#!/bin/sh
if [ $# -lt 1 ]; then
echo $0 [dmg file]...
exit 1
fi
PWD=$HOME/.dmg-password
for FILE in "$@"; do
UUID=$(hdiutil isencrypted "$FILE" 2>&1 | grep uuid | awk '{print $2}')
BASE=$(basename $FILE)
echo File: $BASE
echo UUID: $UUID
security add-generic-password -a $UUID -D "disk image password" -s $BASE -w $(cat $PWD)
done
このようにキーチェインにパスワードを設定したファイルを開こうとすると次のようにキーチェインからパスワードを取り出していいか確認されます。
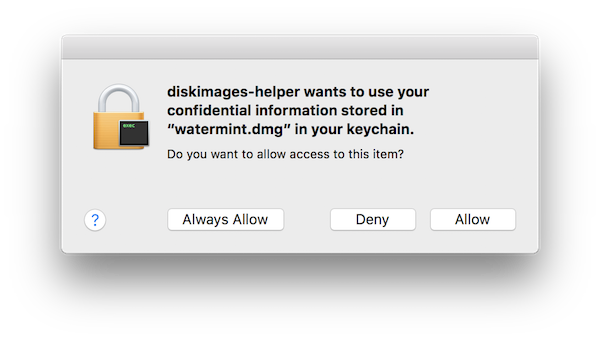
このダイアログをsecurityコマンドの-Aオプションでスキップする手段もありますがすべてのアプリケーションに対して許可を出してしまいます。少し面倒ですが、ここは一手間かけておいたほうがいいでしょう。
12th December 2016 #github #jekyll #migration #tumblr 3年ほど前にWordPressからTumblrへ移行しました。特に大きな問題があったわけではないのですが、最近ソースコードを挿入した記事をいくつか書こうとしたところTumblrのMarkdownではうまく表現され切れない点にすこしストレスを感じていました。表示をあれこれいじっている時間ももったいなくなってきたのでいっそのこと、GFM (GitHub Flavored Markdown)で書けるようなサービスか、システムに移行しようと考え始めました。
あれこれ調べているうちに、どうやらJekyllをつかってGithub Pagesへ移行するのがスムーズそうだなと調べ始めて評価し、次の点で問題なさそうだったので移行することにしました。
- GFMで書ける
- 既存のURL構成を引き継げる
- Tumblrからの記事取り込みもできる
- シンプルなテーマがある
逆に移行に当たってできなくなる機能もあります。たとえばソーシャルメディア連携です。Tumblrでホストしてもらえば、Tumblr上のソーシャルメディアでリブログなど拡散手段があります。ほかには予約投稿やTwitter連携といった機能も使えなくなります。このあたりはトレードオフですが、ソーシャルメディアで拡散していただくよりも、そもそも記事が書きづらくて筆無精になるのであれば優先順位は明らかです。
ソーシャルメディア連携もあとからIFTTTなど何か使えば実現できるでしょうし、予約投稿も必要になれば決まった時間にgit pushするよう何か構成を考えればいいだけです。
移行の効果
移行中のあれこれは後述することにしてまずは、移行によってどういったメリットがあったかみてみます。
WordPressから移行した際にはサイトの速度が劇的に改善しましたが、今回は比較的軽微な差に収まっています。
TumblrでのPageSpeed結果
まずはTumblrでのPageSpeed計測結果から。
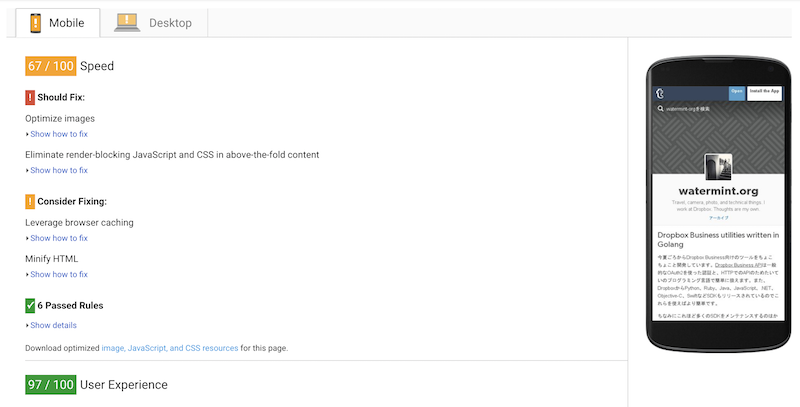
モバイル用のスコアは67点。画像サイズが大きいと警告がでているのと、キャッシュ設定などのところで最適化の余地があるとの判定です。
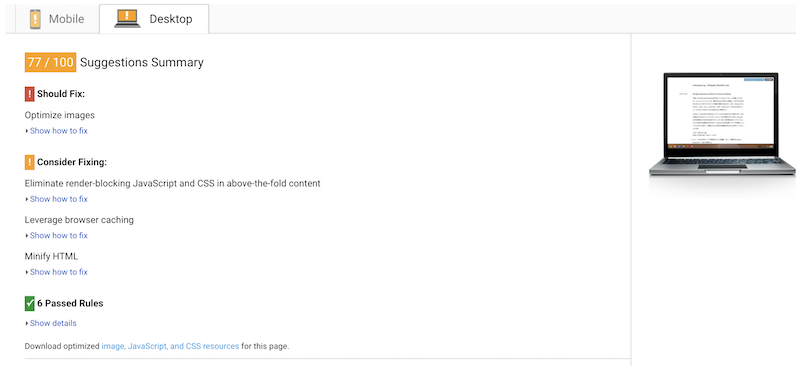
デスクトップ用のスコアは77点。モバイルと同様に画像が大きいと警告が出ています。いずれにしても体感的にはもっさりした感覚は全くなく、表示速度などの不満は特にありませんでした。
Jekyll + Github PagesでPageSpeed結果
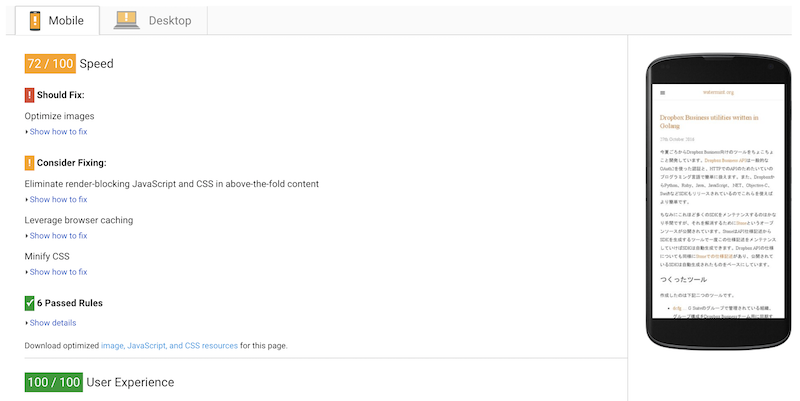
モバイル用のスコアは72点と少しだけTumblrでの表示より改善しています。これはTumblrのインフラスピードとの差というよりは、採用しているテーマのCSSやJavaScriptの差がほとんどだと考えられます。
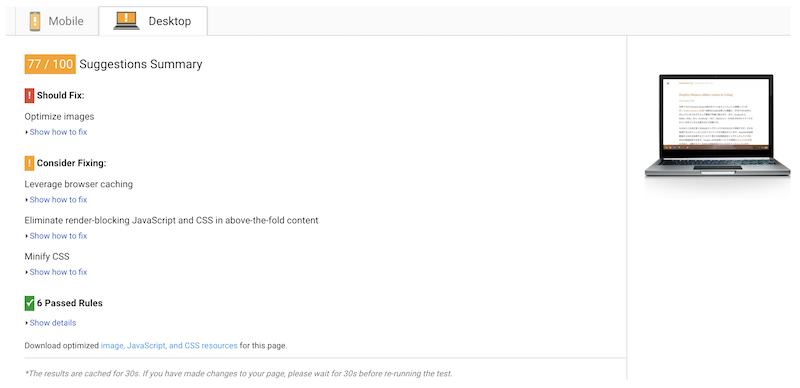
デスクトップ用のスコアは77点とTumblrでの結果と同じです。
その他の違い
Tumblrではモバイル対応していないテーマを使っていたので、TumblrのUIが優先して表示されています。一方、Jekyllで今回利用したLanyonはモバイルフレンドリーなテーマで、今回どちらでも同じLook and Feelでサイトを表示できるようになりました。
移行
移行作業はJekyllの使い方を覚えるところから全部でおおよそ5〜6時間かかったかと思います。Jekyllはかなり活発に開発されているようなのであまりここで細々と手順を書いてもすぐ使いもにならなくなってしまう気がするのでおおまかな流れだけご紹介しておきます。
Jekyll環境の設定
最近はこの手のツールを使うときはすべてDockerを使って独立した環境で実行するようにしています。再現性もありますし、手元の環境もシンプルに保てます。Jekyllを使うには既存のDockerイメージを使えば充分ですが、いくつかテーマを試したりしているうちに依存関係のあるライブラリをまとめてイメージとして持っていたほうが便利だったので次のような内容のDockerfileを作っています。
FROM jekyll/jekyll:builder
RUN apk add --no-cache --virtual build-dependencies build-base
RUN apk add --no-cache libxml2-dev libxslt-dev
RUN apk add --no-cache ruby-dev curl-dev zlib-dev yaml-dev
RUN gem install nokogiri
RUN gem install minima
RUN gem install jekyll-import
jekyll-importは後述のTumblrから記事を取り込んだときに使ったものです。このDockerfileをビルドしておきます。たとえばsiteディレクトリ以下につくっていくならこんな感じにコンテナを実行して、テンプレートを作ったりjekyll-importを実行したりできます。
$ docker run --rm -i $(pwd)/site:/srv/jekyll -p 4000:4000 -t (ビルドしたときのタグ名) bash
今回はあれこれテーマをダウンロードし、jekyll-importでTumblrから記事をざっくり取り込んで表示確認をしながらレイアウトを決定しました。
Tumblrからのインポート
jekyll-importのTumblrについての記事にコマンドが書かれていますのでこれを実行します。 移行といっても今回はTumblrで書いた記事が12記事しかなかったので、ある程度の部分は詳しく調べずに手作業でファイルを修正していくというスタイルで解決しました。
今回実行した際は次のように実行しました。
ruby -rubygems -e 'require "jekyll-import";
JekyllImport::Importers::Tumblr.run({
"url" => "http://(TumblrのID).tumblr.com",
"format" => "html",
"grab_images" => true,
"add_highlights" => true,
"rewrite_urls" => true
})'
最初formatはMarkdown(md)を指定していましたが、うまく記事が取りこめなかったのでhtmlで取り込み、あとで手動でMarkdownに変換しました。
Tumblrでは記事のURLが /post/(記事ID)/(記事タイトル)というフォーマットでしたが、Jekyllでは/(年)/(月)/(日)/(記事タイトル)となるので変換が必要です。rewrite_urlsで相当するアドレスにリダイレクトするファイルを作ってくれるので、リンクはそのまま維持できます。
ただ困ったことに生々されたリダイレクト用のindex.htmlでは/(年)-(月)-(日)-(記事タイトル)へのリダイレクトになっていてうまく動きません。あれこれ探すのも面倒だったのでここは手動で直してしまいました。
grab_imagesという設定があり画像をもってきてくれそうな印象がありましたが、これもうまく動かなかったので手作業で画像をもってきたり、手元に保存してあったものを使ったりして再構成しました。
テーマ選び
いくつかサンプルを見ながら選びましたがシンプルなものがよかったのでLanyonにしました。ほかにもシンプルなデザインのものはありましたが、Lanyonは欲しい機能がおおむね入っていることと、CSSやJavaScriptを含めても全体の構成がシンプルで全体が見渡しやすいことが気に入りました。
切り替え
できあがったJekyllのページ一式をGithub Pagesへプッシュし、あとはCloudFlareでDNSの切り替えをすれば終了です。
Jekyllも開発スピードが速そうなので、開発についていくとしたらかなり大変そうです。ただでき上がったサイトはかなりシンプルなHTML、CSS、JavaScriptと画像ファイルだけで構成されているのでセキュリティー上の理由などで更新しなければいけないケースはかなり少ないと思います。
そういった意味では、一度環境ができ上がってしまえばTumblrでプレビューにあれこれ悩みながら記事を書くよりも手元の環境で確実なプレビューを見てから公開できるワークフローをつくったほうがより生産性が高そうだということで今は満足しています。
画像を含めたオーサリングのワークフローをつくったり、プレビューから予定投稿などまでいろいろ作り込みたいところですがそのあたりはまた今度じっくり作り込んでみることにします。
27th October 2016 #api #dropbox #dropboxbusiness #go #golang 今夏ごろからDropbox Business向けのツールをちょこちょこと開発しています。Dropbox Business APIは一般的なOAuth2を使った認証と、HTTPでのAPIのためたいていのプログラミング言語で簡単に扱えます。また、DropboxからPython、Ruby、Java、JavaScript、.NET、Objective-C、SwiftなどSDKもリリースされているのでこれらを使えばより簡単です。
ちなみにこれほど多くのSDKをメンテナンスするのはかなり手間ですが、それを解消するためにStoneというオープンソースが公開されています。StoneはAPI仕様記述からSDKを生成するツールで一度この仕様記述をメンテナンスしていけばSDKは自動生成できます。Dropbox APIの仕様についても同様にStoneでの仕様記述があり、公開されているSDKは自動生成されたものをベースにしています。
つくったツール
作成したのは下記二つのツールです。
- dcfg … G Suiteのグループで管理されている組織、グループ構成をDropbox Businessチーム用に同期する
- dreport … Dropbox Businessチームに関するメンバー一覧などをレポートとしてCSVで出力する
いずれもCLIツールでシステム管理者が利用する想定のものです。ただ、昨今はシステム管理といってもWindowsだけでなくMacなど様々なシステム環境があります。このように利用用途からかんがえて複数プラットホームで利用できたほうが便利なので、個人的には初めてとなるGolangを採用してみました。
はじめてのGolang
一番最近よく使っていたプログラミング言語はScalaだったので、カルチャーギャップというか、プログラミング言語がもつ信念のようなところに大きな差があって少し戸惑いました。
Scalaのようなオブジェクト指向的にも関数型的にもかけるプログラミング言語の直後ということもあって、Golangの書き方はややまどろっこしく感じます。ただこのまどろっこしさも次第に慣れていくことで、また考え方がわかってきたことでさほど気にならなくなってきました。
どこに書いてあったかソースは失念しましたがたとえば、「関数のなかで、計算量のオーダーが O(1) → O(n)のように変わるような書き方はあえてさせないことで、関数を使う側がどういうオーダーの計算量を常に意識させるようにしている」というような説明がありました。Golangのテストフレームワークがassertをあえて実装していない、といったこともそうですが、プログラミング言語やフレームワークで様々なヒューマンエラーを減らしていこうとする考え方とはまた違う思想を感じます。
この考え方を真に受けてコードを書いていったので、でき上がったプログラムはにたようなforループやif分岐がたくさんでき上がりました。今回、コードをかくに当たってあまり他の方のコードを読んだりしなかったので本流とはだいぶ外れているかもしれません。
パッケージ管理
Golangで戸惑ったのがパッケージ管理です。GoのプログラムはGOPATH環境変数で指定したディレクトリ以下にすべての依存ファイル、そして自分のプロジェクトファイルも置いていくという方式です。
自分のプロジェクトをたとえば、github.com/watermint/dcfg で公開する予定ならば下図のように GOPATH以下に置いていきます。外部ライブラリたとえば、github.com/dropbox/dropbox-sdk-go-unofficialを使うのであればこれらもgo getコマンドを経由して同様にGOPATH以下に配置します。
$GOPATH / src / github.com / watermint / dcfg
ひょっとすると、Goの考え方でAPIは一度公開したならば同じ名前で同じように使えるべき。という信念があるのかもしれません。 この方式で困るのは複数プロジェクトを進行しているときに、異なるバージョンのライブラリを利用したいや、ライブラリのバージョンをしばらく固定しておきたいときにはやっかいです。
また別の環境でビルドする際にも依存するライブラリの管理が煩雑になります。こういった問題に対しRubyであればgem、Javaなどではmaven、gradle、sbtなどパッケージ管理は様々あり、これらで管理するのが当たり前という風なイメージを持っています。Golangでも同じようなものを探してみましたが、いまひとつこれといったものがどれなのかわかりませんでした。
これも今回はあまり細かく調べずに、glideというツールを利用しました。glideをつかうと、依存するライブラリ郡を自分のプロジェクトフォルダ以下のvendorというフォルダにまとめてくれます。バージョン指定も可能ですし、一括してライブラリ郡をダウンロードするなど細々面倒を見てくれます。
また今回つかったdropbox-go-sdk-unofficialは名前の通りアンオフィシャルSDKで、まだ活発に大規模なリファクタリングがおこなわれていてバージョンを固定しないとまともに開発できない。。という現状もありglideによるパッケージ管理はもっとはやく導入しておけばと悔やまれました。
おそらく他のツールでも同様によしなに準備してくれるのだと思います。
ビルド
本格的にコーディングを始める前に、ビルド環境だけは念入りに準備することにしました。ビルド環境のOSのバージョンが違うことで何か問題がでたりするとかなりの時間を浪費してしまいますし、いろんなところで新しくビルドしようとおもったときにも手間がかかります。
今回はご多分に漏れずDockerを使っています。Dockerfileを用意しておいて、Dockerコンテナ上でビルドをしてそのバイナリを手元環境でテストするというワークフローを確立しました。
ついでにTravis CIでもテストが自動的に実行されるようにしておきました。テストカバレッジなども集計するという流れを自動化しておくこともできますが、これもなかなか情報が分散していて地味に手間のかかる作業でした。
これから環境を用意されようと思われる方は下記の.travis.ymlをご参考にしていただければと思います。
language: go
go:
- 1.7
- tip
before_install:
- go get golang.org/x/tools/cmd/cover
- go get github.com/modocache/gover
- go get github.com/mattn/goveralls
- go get github.com/Masterminds/glide
install:
- glide install
script:
- go list -f '{{if len .TestGoFiles}}"go test -coverprofile={{.Dir}}/.coverprofile {{.ImportPath}}"{{end}}' $(glide novendor) | xargs -L 1 sh -c
- gover
after_success:
- goveralls -coverprofile=gover.coverprofile -service=travis-ci -repotoken $COVERALLS_TOKEN
ここで登場するcover、gover、goverallsはカバレッジを取得、集約するためのものです。よく見るとgoverは前職の同僚が作ったものですね。こんなところでお目にかかるとは誇らしいものです。
ところでscript:のセクションはややトリッキーな書き方をしています。これもあれこれ情報を集めながら試行錯誤したものでこれでいいのか微妙なところですがひとまず動作しているのでこれで。。
- go list -f '{{if len .TestGoFiles}}"go test -coverprofile={{.Dir}}/.coverprofile {{.ImportPath}}"{{end}}' $(glide novendor) | xargs -L 1 sh -c
go testというのでカバレッジがとれますが残念ながらgo testでは1つのソースファイルについてのみテストとカバレッジ測定となってプロジェクト全体ではとれません。そこで、ソースコードひとつずつについてgo testを実行してカバレッジデータのファイルを個別につくってあとで結合するという力技です。
Retrospective
今回はCLIツールを作りましたが、利用シーンを考えるとGUIツールもぜひ作ってみたいところです。 GolangでのGUIライブラリはまだこれといった決定打がないようで、ひょっとしたらJavaでつくるか、SwiftをつかってiOSアプリにしてしまうほうがいいのかもしれません。
今回CLIとは別にGinというライブラリを使ってWebサーバを立ち上げるパターンも試作してみました。Play framework等と比べればまだまだツールサポートなども弱いので生産性に課題を感じましたがしっかり作り込めばGUIでつくるよりも将来性がありそうです。
このあたりはまた次回の研究課題です。
1st June 2016 #amazondrive #camera #cloudstorage #dropbox #flickr #googlephotos #nas #photo #storage 
最初にデジタル一眼レフを買ったのがちょうど10年前。カメラも、ハードディスクも順調に増え場所も手間もかかるようになってしまったので写真の整理法から、ストレージの使い方まで半年がかりでやり方をかえていきました。
事前準備
最初はすこし軽い気持ちで始めましたが、結果的にはかなり大掛かりな作業になってしましました。
- データ容量、内容の確認
- ファイル形式の統一
- 重複の排除
- ファイルの分類
- 新しいストレージへの移行 最初から最終形態を設計/想定していた訳ではありませんが、随時微調整しながら進めています。
整理を始める前のデータと容量
ハードディスクを整理してみると、ハードディスクはNASに搭載しているものもあわせると15本、NASは2台、総容量は30TBと一般家庭にしてはかなりの容量です。それぞれのディスクのおおよそ6〜7割は使用中で単純計算で18TBものデータが存在していました。
ただそのほとんどはバックアップ用途の重複保存です。同じデータを最低2本以上のディスクに保存することにしていたので、単純計算でデータ容量は9TB程度です。 またさらに、写真管理ソフトの形式によって重複している部分もありました。写真の管理は2001年ごろからはiPhoto、2007年ごろからはAperture、2013年からはCapture Oneを使っていました。2013年は少しだけLightroomも使っていたのでこのデータもありました。
Apertureのサポート終了に伴う移行では最終的に、Capture Oneに落ち着きましたが慣れの問題もあり最終的にCapture Oneに一本化できたのは2014年後半でした。この間、データはAperture形式とCapture One形式の二通りのライブラリとして管理していました。
ここまでの見積もりメタデータやサムネイルファイル、重複などををおおまかに調査したところ最終的なファイルサイズはおおよそ3〜4TB程度になると見積もりました。
整理を始める前の写真
もう一つの問題点は、簡単には狙った写真が見つけられないということです。連射した写真や似たような構図の写真が大量にあると、毎回無視できないほど時間がかかります。多いときには1日に1,000枚以上撮影していることもあり写真を見直すことがおっくうになってきますが、そのように大量に撮影しているときにいい写真があるのでまたもどかしい気持ちになります。
たとえば3年前の旅行で撮った写真を加工して印刷したい、といったときに該当のRAWデータを見つけるのは結構な手間がかかりました。1週間の旅行で5,000〜7,000枚程度の枚数にはなるので、ApertureやCapture Oneのライブラリを開くだけでもしっかりと時間がかかります。
撮影当時にApertureやCapture Oneで調整した結果からさらに編集したいとき、目的のApertureライブラリやCapture Oneセッションを探し出すというのはかなりの労力がかかりました。仕方なく、現像済みJPEGから再調整するということもありましたがせっかくRAWで保存してあるのに活用できないのはもったいない気がします。
このように整理を始める前はデータも、写真自体も管理がばらばらで再利用するのがとにかく面倒で、一念発起しないとできない。という状況でした。
目標と方針を決める
写真を撮るのは楽しいですが、整理するのは面倒だと感じています。写真は趣味で、ビジネスとして撮っているわけではないので、整理に割ける時間も限られます。趣味の範囲という前提に立つと「写真を撮るのも、後から見ることも楽しい」ぐらいが目標となり、このための雑務を減らし、秩序をつくっていくことがアクションとして考えられます。
この目標実現のために最初に決めた方針は次のようなことでした。
- 資産として再利用できるようにする。
- フラットな構造に管理する。たとえば、複数のディスクに分散しないようにする。
- すでに機械化されている、または将来機械化されそうな作業をしなくて良いようにする。
NASからの移行
まずは重複を排除しつつ、データを一ヶ所にまとめることにしました。3年まえからほとんどのデータは、NASのDrobo 5N (実効容量9TB)にまとめていました。このNAS上にすべてのディスクにあるデータをまとめ、整理していくのが順当ではあったのですが一つ問題がありました。
Mac OS XはNASへのアクセス性能がきわめて悪いことです。データ転送などある程度まとまった処理はさほど悪くないのですが、ファイル一覧などファイルを探す処理が極端に遅いのです。 Finderでファイル一覧を開くだけで数十秒〜数分かかることもあり作業に大きな支障がありました。通常、NASをMac OS Xから参照するとAFP (Apple File Protocol)で接続されます。これを、SMB2というプロトコルに変更すると若干改善するように見えるのですが、それでも体感速度はさほど変わりませんでした。Drobo 5NではmSSDを使ったキャッシュを搭載することができますが、このキャッシュを搭載してみてもさほど体感上変わりはありませんでした。
かわりに、Mac OS X上のVirtualBoxにUbuntu Trustyをインストールし、SMBクライアントでマウントしてみると見違えるように高速に動作し原因はMac OS Xの問題とほぼ限定されました。実際に、Mac OS Xからrsyncなどのコマンドでファイル転送してもシステムコールレベルでNAS側に制御ファイルを作成したり削除しているような振るまいが見られこのオペレーションが低速につながっていると想像できました。
作業をUbuntu上で行うことも選択肢にはありましたが、Capture OneやApertureなどMac OS X上のアプリケーションも利用する必要があることから、Drobo 5Nに集約することはあきらめて6TBのハードディスクを新たに購入しここにすべてのデータを集約することにしました。
Drobo 5Nの純粋な性能と比べても、ネットワーク越しのアクセスとUSB 3.0の直接接続では大きくスループットも違いがでます。
データのコピーとデータ形式の統一
データのコピーは基本的にすべてrsyncコマンドを使いました。信頼性があるのと、中断せざるを得ないときにも停止して安全に再開することもできます。Mac OS Xの性能問題もあり、コピーは基本的にUbuntu上で行いました。それでもDrobo 5Nからの転送はおおよそ1〜2週間程度かかったと思います。
最初にApertureライブラリを転送しました。Capture OneにApetureライブラリをインポートする機能もあるので、こういった機能も使いつつJPEG、TIFF、RAWファイルなどの元データとメタデータをApertureに依存しない形式に変換していきました。この作業も1〜2週間かかったと思います。
Capture OneはEIPというファイル形式で出力することができます。EIPはRAWデータ、メタデータ、調整データをすべてひとつのファイルにまとめたものです。EIPファイルさえあれば、調整データもメタデータも含め写真1枚ずつ開いて加工することができます。EIPファイルの実態はZIPファイルで、中にはRAWデータや調整データを含むファイルが格納されています。
Apertureのライブラリ、Lightroomのライブラリ、Capture Oneのライブラリはそれぞれライブラリとして一つ大きなパッケージとして管理するので操作が高速であったり、アルバム管理など便利ですがEIPファイルのように1枚一枚別々に管理できるとApertureやCapture Oneなど専用ソフトでなくても操作できるので、後述の重複排除など操作では重宝します。
このように、Capture OneのデータはEIP、ApertureのデータはRAW + XMPファイルとしてエクスポートして一ヶ所にまとめることができました。
重複排除
重複排除にはGeminiというアプリケーションを利用しました。ファイル数が多すぎるとUI操作がもたつくこともありますが、操作がわかりやすいのとファイルをプレビューしながら操作できる点が大きなメリットです。
Geminiでおおまかに重複排除したあとは自作のスクリプトで重複排除を進めました。RAWから現像したファイルはいったん削除することにしたので、EXIFデータを見ながら日時、カメラなどのデータが一致するJPEGファイルを削除。他には、前述のEIPファイルではZIPファイル中にRAWファイルがあるため、Gemini等の重複排除では期待通り重複を排除できないためEIPファイル中のRAWファイルデータを読み出して比較しながら重複排除するスクリプトなどを作成しました。
99%以上のファイルは有効なEXIFデータが入っているのですが、かなり古いデジカメで撮影した写真などデータが含まれていなかったり、EXIFなどのデータが破損している場合があったのでこういったファイルはそれぞれ目視確認しつつ作業を進めました。
このような作業を繰り返し重複排除が終わったときには13万枚程度の写真ファイルが整然と並びようやく全貌が明らかになりました。
分類する
写真をおおまかに2つのグループにわけることにしました。1つは、何度も見返したい写真。もうひとつはそれ以外の写真のグループです。
何度も見返したい写真は比較的しっかりバックアップがとられるように管理したい写真で、それ以外の写真は最悪なくなっても気にしないといったポリシーで管理することにしました。
グループ分けの考え方
「すでに機械化されている、または将来機械化されそうな作業をしなくて良いようにする。」という方針から、写真のレーティングで機械化されそうなところは機械にたよることにしました。
たとえば写真のなかの顔認識についてはかなり技術的に進んでいて、特定の人が写っている写真を撮り出すということは今日たやすい操作です。この画像認識技術はまだ多少精度の問題もあります。生物や植物の図鑑をつくるような目的である程度厳密に分類をするといった用途には向きません。今回の目的は必要な写真をすぐ見つけたい。というぐらいですから、多少違う写真がピックアップされたところであまり影響ありません。
Siriのようなアシスタントに「AさんとBさんが写っている去年の集合写真をさがして」とか「Cさんが写っている沖縄の海辺の写真を探して」といったら数枚がピックアップされ、ピックアップされた数枚から「ピンボケしていないものだけ」といった絞り込みもそう遠くない未来に実現するでしょう。
すでにGoogle Photosやflickrでも機械学習などの成果から「建築物」とか「食べ物」と自動的に分類したり、GPSデータがなくても建造物などから場所を推測してタグ付けするといったサービスが提供されていますのでこういった分類は手作業で時間をかける必要はありません。
今回の写真整理では利用しませんでしたが顔と名前、人のつながり、時間や場所とイベントといった付加情報のデータベースについていえばfacebookが圧倒的に大きなデータベースを持っているので、facebookが面白い提案をしてくるかもしれません。
一方すぐに機械化できないと思うのは個人的な体験による重要度の重みづけです。何の変哲もない風景写真だが自分には印象深いとか、ピンボケしているが人生の大きなターニングポイントのタイミングを象徴するとかデータとして記録していないし、定型的な表現の難しい体験による重要度はいかに機械化による分類はやや難しいでしょう。facebookやtwitterなどに記録されたイベント、発言など複合的に機械学習することでおもしろい写真の組み合わせを提案する。といったことはできたとしても、自分の印象に残ったあの写真を探す。というのとは少し方向性がちがうと思うからです。
レーティング
こう考えると機械化できるところは機械に任せるとして、印象深いシーンのみをピックアップして分類していくということにしました。ピックアップする際にはApertureやCapture Oneでは★1〜5のようにレーティングをつけることができますが、これを利用しています。
過去にもレーティングをつけていましたが統一した基準をもっていませんでした。このため時期によってほぼ★1〜3しかつかっていないとき、★3を平均として1〜5の範囲で使っているときとばらつきが生まれていました。前述の通り、個人的な体験による重要度を尺度とするので時間の経過とともに重要度が下がっているものもあれば、重要度が上がるものもあります。
たとえば、スキューバダイビングをしていて最初のころは何でもすべて珍しい魚、地形と感じ、重要と位置づけていますが、次第に慣れてくると、同じ魚/地形でも天候や構図などが優れた場合が重要であるというように変化することもあります。
レーティングは新しく★3を平均点として、★4を優秀、★5は最優秀としてつけることにしました。厳密な定義はありませんが、★5は印刷して壁に飾っておきたいような写真、★4はパソコンやスマートフォンのデスクトップ画像にしたいような写真といった感覚で点数をつけています。
★2は★3相当だが構図が似ているのでボツ、★1はピンボケや構図がかなりわるいといった使い分けです。全部の写真にレーティングをつけると面倒なので、★3以上だなとおもうときだけレーティングをつけ、同じシーンで似たような構図が多いなとおもったら★2に下げるといった調整をしています。
枚数の比率としては★1〜★2相当の枚数くらべ★3以上の枚数が1/10以下になるよう目標として、全部で13万枚ありましたので★3以上は1万枚以下を目標として調整しました。この作業が最も時間がかかり2ヶ月以上かかりましたが結果として★3はおおよそ6,000枚、★4はおおよそ700枚、★5は60枚と目標通りの枚数に調整できました。
10数年分で7,000枚、デジタル一眼レフを使い始めた近年でも1年当たり1,000枚前後となったので見通しはかなりよくなりました。
最終的に容量にして★3以上の写真は170GB、★なし〜2の写真は2TB弱とかなりコンパクト化することができました。
ストレージ
写真の保存としてこれまでRAWデータは自宅のNASやUSB接続のハードディスクに、現像済みのJPEGデータはflickrに保管していました。
今回はRAWデータも含めてクラウドストレージ上に管理することにしました。使ったのは次のストレージです。
- Amazon Drive : Amazonプライム会員になると写真データは無制限に保存することができるのでCaptureとした★2以下の写真を置きます。無制限となるのはJPEGだけでなく、NEF、ARWなどRAWファイルも対象となりますが、EIP形式などは対象外なのでEIPではなくもとのNEF/ARWなどのRAWファイルに変換しておきます。
- Dropbox : EIP形式にしたRAWファイルと調整済みの現像JPEGデータを保存しておきます。★3以上の写真のみ置きます。Dropboxはバージョン履歴をとれるので、編集履歴も自動的に保存されるのが利点です。
- flickr : flickrにはほぼすべての現像データがすべて置いてあります。flickrは使い始めてちょうど10年ほどになりますが、容量無制限のころのProアカウントを利用しているので気兼ねなくアップロードすることができます。flickrも機械学習による自動分類ができるので発見目的に利用しています。
- Google Photos : オリジナル解像度ではなく、Googleの設定した解像度以下であれば無制限に置くことができます。機械学習により自動分類されるのでここにも★2以下の写真を置きます。 多くのクラウドストレージは1TB程度以内までと容量制限がありますが、今回★3以上と★なし〜★2のように分類したことで★3以上の部分(約170GB分)については選択肢が大きく広がりました。Dropboxのようなクラウドストレージを使えばバックアップも気にすることなく自動的にとられているので大量のハードディスクやNASを管理する必要がなくなりました。
新しいワークフロー
こういった整理を進めながらも写真は日々ふえていきましたが、最終的な保存場所がきまったことでワークフローが整いました。写真を撮影したら、新しいCapture Oneのセッションを作成します。このCapture OneのセッションファイルはDropbox上に置き、すべてのファイルがDropbox上にバックアップされるようにします。
次にレーティングをつけて、★3以上の写真については調整と現像を行いEIP形式への変換などをしたうえで所定のディレクトリにエクスポートします。現像データはflickrにアップロードします。 ★なし〜★2の写真についてはRAWデータを所定の場所におきAmazon DriveとGoogle Photosにアップロードされるようにします。
ここまでの作業が完了したら該当のCapture Oneセッションは削除します。Dropbox上に削除済みファイルも保存されているので必要とあらば再度取り出せますから、心置きなく削除してしまいます。
整理をおえて
今回の整理をおえて当初もくろんだ通り、再利用については非常にやりやすくなりました。2012年の旅行写真をとりだして編集するといった基本的な操作がストレス無くできるようになりました。Google PhotosをつかってAさんが写っている写真、といったような写真のとりだしかたもできるようになりました。
まだ新しいワークフローにしてまもないこともあり、AmazonやGoogleへのアップロード作業など一部自動化できていない部分もありますが最初からDropboxに保存することでクラウド上で処理できることも多くなりました。
Dropboxに追加されたら自動的にデフォルトのレシピで現像して、Amazon、Google、flickrにアップロードするとか、レーティング情報が追加されたら長期保存対象として所定のディレクトリに置くといった仕組みを作ることもできると思います。
16th April 2016 #card #graphilo #liscio1 #mdnote #mdpaper #midori #moleskine #note #paper #productivity ちょうど使っていたノートの残りページが少なくなってきたタイミングで、書籍「知的生産の技術」を読んだことが影響して、使うノートをカード(断裁紙)に変えてみることにしました。知的生産の技術は初版が1969年と約50年ほどまえの内容ですが、今回は加えてパソコンやスマートフォンをつかったデジタル端末と連携した使い方を整理してみます。

カードとは
本エントリーでいうカードとは、特別なものではなくノートのように綴られていない1枚一枚ばらばらの紙(断裁紙)のことです。「知的生産の技術」ではB6サイズで、やや厚みのある紙(105kg)、9mmの罫線がはいったものが紹介されています。これは「京大式カード」としていまでも文具店で売られています。今回はいくつか検討した結果A5サイズ、5mmドット方眼を使うことにしました。
このような紙の片面だけに内容を書きます。ややもったいない気がしますが、両面は使いません。カードの使い方や、カードにつかう紙については後述します。
なぜカードにするか
2008年頃からノートは[ミドリのMDノート(http://www.midori-japan.co.jp/md/)というのを使っていました。サイズはA5のものを主に使っています。

素朴なデザイン、クリーム色がかった紙、万年筆で書いたときも気持ちが良いなどいくつか気に入る要素があったのがこの8年ほど使い続けていた理由です。ノートは主に議事メモや計算、思考実験などいろいろな用途に使っていました。ただ近年、いくつか不便だと感じるところも増えてきました。
「知的生産の技術」にもいくつかノートよりもカードの方が優れている点が紹介されていますが、読みながら自分で気付いた理由を以下にご紹介します。
前ページに書いた内容を振り返りながら考えるのが面倒
考え中、まとめ中の内容を前ページと何度も往復しながら進めるのはかなり面倒です。できれば10ページ分ぐらいの情報量を一覧して考えたいのに、何度もページをめくらないといけないので考えが中断されてしまうのがもどかしいところでした。
特に多かったのはアプリケーションの設計をしているときにあるページにはデプロイ図、あるページにはクラス図、あるページには重要な処理のシーケンスなどを描いていたとしてこれらが一度に参照できないと一貫性があるかどうか確認できないといったケースです。
対策としてよりA4/A3サイズとか、大きめの画用紙を用意するなど紙を大きくすることで一部解消していましたが、保管する際にサイズが違うと扱いに困ったり、必要なときに大きな紙が手元にないなど完全な解消とは言えませんでした。
カードであれば机いっぱいにカードを広げてあれこれ比較しながら考えることができます。ちなみに、カードの両面を使ってしまうとこのように広げて比較するときに結局ぺらぺらめくりながらとなるのでノートで味わった不便さを引き継いでしまいます。もったいないですが贅沢にカードを片面だけを利用します。
不必要な情報を持ち歩きたくないときに困る
特に仕事上のメモが入ったノートをどう取り扱うかは悩ましいところです。パソコンやモバイルデバイスであれば暗号化やパスコードロック、遠隔から削除するなどいくつも防御手段があるので安全ですが、紙媒体ではどこかに置き忘れてしまうとどうにもなりません。
このため、仕事で使うノートは基本的に会社の机や棚に入れて施錠しておくことになります。用途ごとなどでノートを分離しすぎると持ち歩きや管理が面倒なのでできれば一冊にまとめたいのですが、会社のセキュリティーレベルで保管しておきたいのであれば分離するしかありません。
仕事用ノートには仕事上のメモだけではなく読書備忘録などを記録することもあるのですが、読書備忘録だけ持ち帰りたくてもやぶってもって帰るわけにも行かないのでやむなく持ち帰らないという選択をするしかありませんでした。
カードであれば行き先と用事にあわせて取捨選択できるのでこういった悩みがなくなります。仕事用カードは仕事場に施錠しておいておき、残りの読書備忘録や旅行メモなどはいつでも好きなように持ち歩けます。ささいな悩みもチリも積もれば大きなストレスになるのでカードの利用は大きな安心感があります。
スキャンしづらい
ノートは物理的に保管スペースもとるのと、持ち歩かないと参照できないのでやや不便です。 先月読んだ本から思いついたアイデアって何だったっけ? といった振り返りができないのではせっかくメモしても役に立ちません。こういうデータはDropboxなどクラウド上に保存して持ち歩きたいのでスキャンしています。
スキャンするのに1ページ、2ページ程度をスキャンするのはノートでも簡単ですが複数ページとなると面倒です。断裁紙であればScanSnapなどのスキャナで連続してスムースにスキャンできるのでデジタル化の手間が省けます。なお断裁紙でもパンチ穴があると穴にひっかかってうまく紙が送られないということもあるので穴をあけずに使います。
カードの使い方
カードの使い方は「知的生産の技術」に紹介されている内容をほぼ踏襲しています。次のようなことを心がけて使います。以下のような使い方を心がけているのはメモや考えを再利用しやすくするためです。
1枚に1件のトピックのみ書く
慣れるまで抵抗感がありますが、余白があっても別のトピックであれば別の紙に書きます。これは自分のまとめた情報を取捨選択したり並び替えたりして新しくアイデアをまとめていくことを重視するためです。
カードの片面のみ使う
いくつかのカードを一覧にして比較検討したいので両面使ってしまうと煩雑になります。また、異なるセキュリティーレベル(仕事用と個人用)の情報が混じったりすると管理が煩雑になるのでカードは片面だけを利用します。
カードにはなるべく文章で書く
ある程度時間が経つと自分で書いた文章でもメモの意味がわからなくなり、メモの意味がなくなってしまうといったことがあります。 議事録など議事進行に合わせてある程度速記的に書いたものは新たなカードに文章としてまとめなおしておきます。
ただ、「知的生産の技術」が書かれた時代(初版1969年)と違い現在ではパソコンやスマートフォンなどを用いて手書きよりも効率良く長文を書くことができますので、かなり長文になるようであれば迷わずパソコンを使ったほうがいいでしょう。 議事録であれば参加者などに共有する場合に手書きより電子データの方が便利です。紙に書いたメモと電子的に書いたメモをどう管理するかについてはまた別の機会に書くことにします。
日付(年月日)とタイトルを書く
カードがある程度たまって整理するときに日付やタイトルがないと内容の判断が面倒になります。いま考えようとしているトピックと関連があるのかないのか簡単に判断できるよう、面倒でも必ず記入しておいたほうがいいでしょう。また同じトピックについて複数枚ある場合は連番を振っておくべきです。
「知的生産の技術」にも書かれていましたが、日付については月日だけでなく年も書いておくべきです。個人的にも3〜4年前からは年も含めて書いていますが、年を記入していなかったときのメモは再利用するのに苦労します。特に時系列にそって整理し直そうとすると大変です。
日付についての書き方はいろいろありますが、個人的にはISO 8601の拡張形式 YYYY-MM-DDを使っています。これはある程度好みの問題ですが個人的には下記のような理由でYYYY-MM-DDにしています。
- YYYYMMDDのように区切りがない場合は判読しづらい。
- YYYY年MM月DD日や平成YY年MM月DD日のように漢字や和暦を使ってもよいが、手書きのときには面倒。
- スキャンしたカードのファイル名も合わせたいが、YYYY.MM.DDのようなドット区切では一部ソフトウエアでうまく扱えないことがある。ハイフン区切りでは問題が起きにくい。
- May 1st, 2016のように英語表記では電子化したときのファイル名を使った時系列のソートが面倒。
カードに使う紙を選ぶ
カードに使う紙をどれにするかあれこれ考えました。文具好きにはたまらない時間です。単に趣味の選択というほかに、カードとして利用するためにいくつか条件を考えました。
調達しやすさ
整理して再利用していくため、または記録を資産として残していくために利用したいので10、20年と長期的に販売されているものを選びたいものです。そのほかに、出先で紙が足りなくなって追加で手に入れられないというのももどかしいですから調達しやすさは重要な評価ポイントです。
厚さや紙質は多少変わっても構わないのですが、サイズがばらばらになると扱いづらくなるので調達しやすいサイズの紙を選ぶことにします。モレスキンのラージサイズ(A5より少しスリムな130x210mm)は持ち運ぶときに絶妙なサイズでとても魅力的だったのですが、断裁紙の状態で販売されているのをみつけることができなかったので断念しました。
「知的生産の技術」でふれられているB6サイズの京大式カードは都内の文具店を何店舗か回ってみたところ、きちんと数えていませんが2〜3割程度の店舗でおいているような印象がありました。
takeopaperのようなさまざまなサンプルから好みのサイズにカットして納品してもらえるようなサービスもあります。このため必ずしも標準サイズにこだわる必要はありませんが収納文具など周辺をととのえることまで考えれば標準サイズのほうがより手軽です。
どのサイズにするか
調達しやすいサイズとなると必然的にA4、A5、A6、B5、B6サイズなどの標準的な断裁紙を選ぶことになります。標準サイズを使えばクリアフォルダーやファイルなど収納文具も無理なく使えるので効率的です。
京大式カードのようにB6サイズは野外など立った状態でも使うことを想定して小さすぎず大きすぎずという選び方に適しています。
一方、いま野外など立った状態でメモするのであればスマートフォンを使うのが最も手っ取り早く、煩わしさがありません。このため、野外などで軽くメモをしたいという用途は縮小し、デスク上で使うことを主な利用シーンと想定しました。
このためB6サイズ(128x182mm)よりやや大きいA5サイズ(148x210mm)を使うことにしました。もともと使っていたMDノートもA5を最もよく使っていたので使い慣れているということもあります。
紙選び
まず、ちょうど紙選びをしていたときに日本橋三越の世界の万年筆祭という催事に神戸派計画というブランドが出店していたのでのぞいてきました。GRAPHILOという万年筆用紙が展示されており、試し書きもさせていただきました。ちょうどA5サイズの断裁紙もおいていたので、横に置いてあったLiscio-1と合わせて買ってきました。

価格はLiscio-1が100枚で800円(税抜)、GRAPHILOが50枚で800円(税抜)とGRAPHILOはかなり高級感があります。厚みや重さなど詳しく書いていないのでわかりませんが、目測では厚みはどちらもほぼ同じで、おそらくモレスキンやMDノートなどともさほど大きな変わりはないかと思います。
後から知ったことですが残念ながらLiscio-1は在庫限りのようで今後はGRAPHILOに統一されていくようです。どちらも100枚ずつ使ってみた時点の好みでは、Liscio-1のほうが好みだったのでこれは残念でした。GRAPHILOは非常になめらかで気持ちいいのですが、すこしざらつきがあったほうが個人的には書きやすいと感じたためです。
次に試したのがMDノートを出しているミドリからMDノートの断裁紙版、MD用紙A5 100枚パックです。こちらはオンラインストア限定で売られていますが100枚で400円(税抜)と神戸派計画と比べてもかなり手ごろです。MDノートだと176ページ(88枚)で800円程度ですからノートと比べるとさらにお得感があります。

MD用紙がいつまで手に入るかはわかりませんが、ひとまず今回の紙選びではMD用紙をメインにすることにしました。
持ち運び
ノートのように表紙がないと紙がぐちゃぐちゃになってしまうので持ち運び用の工夫が必要です。最初はA5サイズのプラスチック下敷き2枚でサンドイッチにすればよいかと考えていましたが、実際に文具店でプラスチック下敷きをみてみると比較的やわらかいものがおおいのでカッティングマットを使うことにしました。

カッティングマットだと硬さも申し分なく、適度にしっとりと手になじむのが好印象です。このカッティングマットをゴムバンドでとめて持ち歩いています。十分に硬いので、クリップボードを使うように立ち姿勢でメモを取ることもできます。
ドット方眼
方眼の大きさや濃さなどかなり好みの分かれるところだと思います。モレスキンの方眼は個人的には方眼が濃すぎるので好みではありません。MDノートの方眼は適度に薄く、あまり主張しないので長年気に入って使っています。
罫線のいれかたも、端から端までびっしり線がかかれているのはあまり好みではありません。厳密に書かなければいけないという印象があるからかもしれません。
MDノートがイメージしている原稿用紙のマス目ようにひとマスごとわずかに隙間が空いているほうが圧迫感を感じないので書きやすく感じます。
最初、断裁紙を探す際も好みの方眼のはいったA5サイズものを探していましたが全く見つかりませんでした。このため方眼についてはあきらめて、無地の断裁紙を買った上で自宅のプリンターで印刷することにしました。
個人的には5mm方眼でぱっと判別できるかどうかぎりぎりぐらい薄い方眼が好みです。印字するときも薄ければインクをあまり使わないので経済的です。

ノートからカードへ変更した効果
ノートからカードにしたことでどのぐらい生産性が上がったとか、時間が節約できたかといった定量的なデータはとらなかったのではっきりとはわかりません。ただ、前後のページをぱらぱらめくるような思考の妨げがなくなったこと、情報の取捨選択が簡単になったことは実感として確かなものがあります。
スキャンしたカードのファイルをどう管理するか、スキャン済みのカードをどう整理するか、そもそも大量のカードをどう管理するかといった課題についてはもう少し長期間試行錯誤する必要がありそうです。
考える時間と質
成果物の品質があがったかどうかの客観的判断は難しいところですが、自己満足レベルではかなり効果があったと思っています。「知的生産の技術」にもふれられていますが、なにかものを作り出すための時間においてはいかにわずらわしさをなくすかが影響を与えます。今回ノートからカードにしたことによって、本エントリーでふれたいくつかのわずらわしさがなくなりました。これにより思考が途切れることなく考えることに集中できるようになりました。